Local, offline LLMs on CPU (&GPU if you're rich), laptops, RPis and potentially phones
On a previous post HERE I described my first foray into using ollama as an LLM Engine on a Raspberry Pi 5 device.

This time, I'm going to describe how to install / use that ollama Engine with a front-end UI.
Show options where you could use docker containers to run the components
Show how to use native installation onto a laptop (VM Ubuntu) as it's just simpler
Then, how to modify that UI code, rebuild it & see the changes.
"Why Tony? Why?"
Y'know, if you have to ask "Why?" then you don't understand. Well, the reason being, I did some work about 1-year ago in relation to LLMs, very cutting-edge, very new & never done before, pretty ground breaking stuff. However, it was too far advanced that no-one really understood it, quite a lot still don't. Now, 1-year later, people are saying, "wow!amazing" about things that are loosely similar to what I did a year ago... sigh... the burden of being a geek. So, this time, I'm just going to record what I've been doing, yes, this has been done, used, and now collecting dust - however, I have had to set this up a couple of times & my golden rule is, "if you do it more than 3 times, create a function for it" - well, it loosely relates to, "if you have to do this again, write it down so you can come back & follow the instructions".
"So what is it? and why?"
It's just a pattern where you can install an LLM Engine (ollama) that is built very much like docker, ie. the code pulls down the LLM models in a similar style to how docker pulls down container images.
(If that didn't make sense, go away & go figure it out. I'm not teaching you)
Once you have the many different LLM models downloaded & available, you can then use a different UI to interact with the ollama models. You can actually interact with the ollama Engine via REST API calls - so you could put a node-red API layer in-front of it and drive it "headless" - will come in useful later on.
For now though, I'll just use ollama-web-ui as the UI interface as it is nicely coded and covers pretty much all you need and as it's open-source can be extended (which we shall do).

I have to address the icon on the corner of my desktop that says, "GPT4All". Yes, I installed that last year at some point during my inverstigations, however it was a bit of a walled-garden approach, it was great - not knocking it, however, I've not returned back to it to see the new benefits, will upgrade in the background now:

Okay, back to ollama.
From the ollama website

NO AI VENDOR LOCK-IN & MONETISATION GOING ON HERE. I'm looking at you M$oft, AWS, Google and especially the ironically named "openAI" that is so closed it's hilarious.
Execute that command from the CLI (of course this is UBuntu, why use anything else?)

That's it. It downloaded the ollama Engine app, put it into the executable folder and made it available for CLI calling as a service. You can now either invoke from the CLI or the REST API.
However, you need some LLM models to be available to use first:

It's as simple as running the following command:
$ ollama pull llama2
Repeat that for however many models you want - you don't need to get all of them, in fact, if you check out the descriptions you should only really download & use the models that look of value to what you are going to want to work with. For instance, no need to download the "code generation" model if you're never going to ask the LLM model to help you write some code. confession time: I've never used one of those, maybe I should? I don't know, maybe it's the GenX-er in me, it feels like cheating in some way. It shouldn't, I mean the LLM model has just been trained on a bunch of reference info off the internet (maybe I don't trust those sources? reddit / stackoverflow / etc...?) rather than a bookshelf of approved & authored books from O'Reilly that I can trust. Maybe that's more of a "me" thing, I don't have clarity, therefore I don't "trust" the output, maybe I'm just being resistant as somehow my brain is thinking that the 25-30years of coding experience and know-how is now worthless, someone with 0 (zero) experience / previous knowledge can now type a sentence and describe what they want the code to do & the code will be written perfect first time & just work and they don't need to know anymore than that. Yes, job done - but that's probably the irksome point - after how many iterations will it take for "people" to lose that traceability of "knowing", yes, they'll get the answers, but they won't know how - and in essence they'll actually get "dumber", not smarter.... that was a nice tangent, but oh look, the download has finished:


A quick test can be made from the CLI:

Yep, that works okay.
Right, now onto the ollama web ui - oh, look at that - told you this was fast moving. That was LAST WEEKs name, this week it has evolved (probably quite rightly) to now be called Open-WebUI.
I can understand the logic - it was tying itself to the ollama Engine a bit in the name & this name change gives the options to switch out the back end Engine to whatever you want. You could see that in the earlier codebase, it was allowing you to call out to OpenAI GPT if you want, also to call out to local LLMs, so the design was already evolving, logical for the name / branding to follow.
Right, time to take a look HERE.

Looks simple enough, just follow those instructions. Okay, that was mean of me - don't do that, let me save you a little bit of a headache / time...... you do do "most" of what it says there, but follow these steps:
Firstly, let's check what we currently have installed:

Nearly, but not quite.
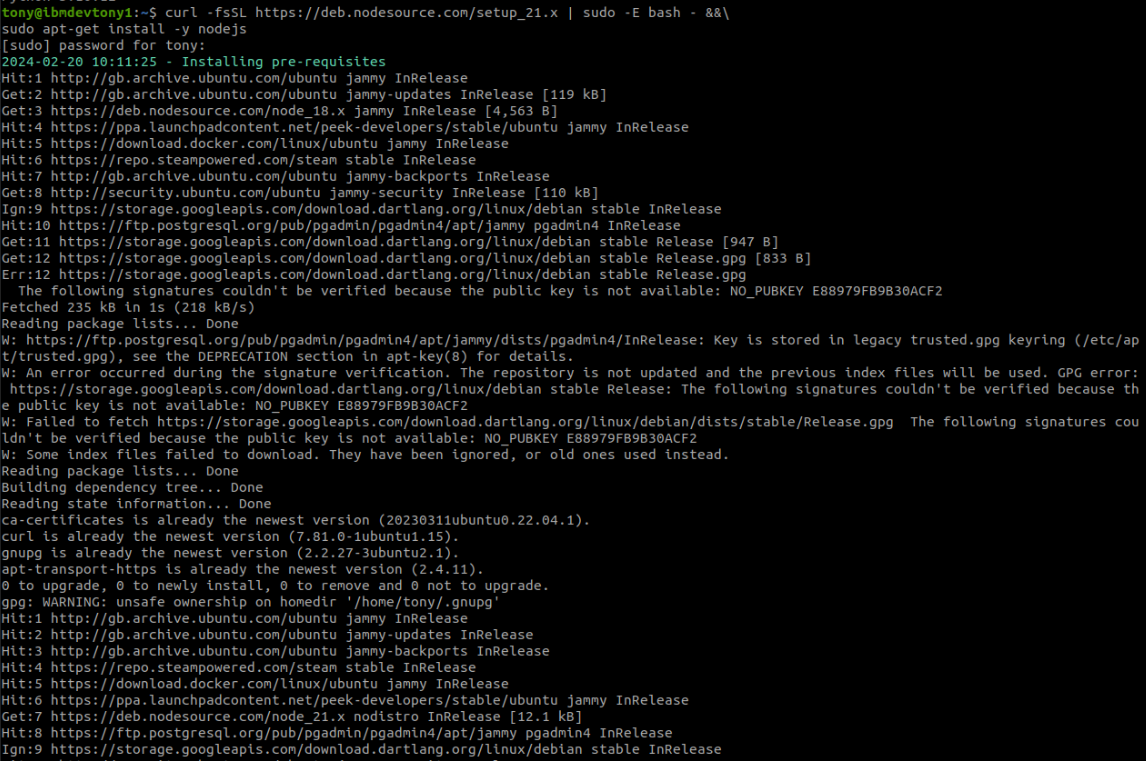
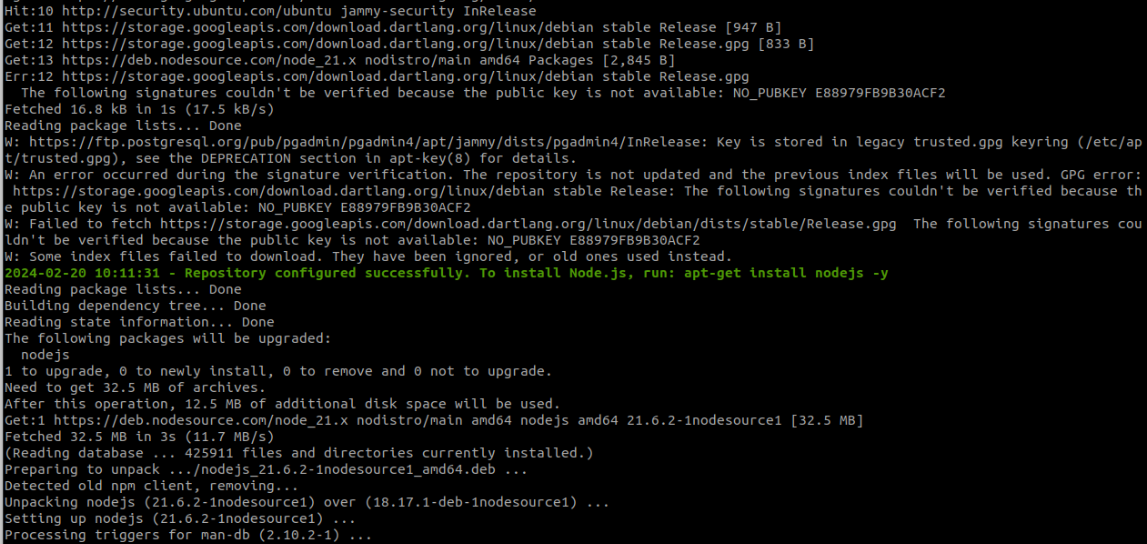
First, let's upgrade NodeJS. Visit HERE.
curl -fsSL https://deb.nodesource.com/setup_21.x | sudo -E bash - &&\ sudo apt-get install -y nodejs
Now, this is more interesting.....Python is 3.10 and NOT 3.11.
One way to handle this upgrade is to basically upgrade the UBuntu distribution to 23.x. I actually did this on my personal Honor laptop, it was a bit of a faff / hit & miss and a late night to get there, but I managed it and it all works well... however..... pfffhh.....
This is partly why I don't like Python. It reminds me far too much of the DLL-hell days of the Windows 95/98-era, when loads of people distributed their Visual Basic 6 apps with a bunch of .dll files for their code to work, but that overwrote / conflicted with other apps etc... EXACTLY the same thing with Python libraries & versions. Why is it happening again? well, the people who remember it from the first time - and solved it - are being ignored, "'cos they are old" or they've retired & don't give a sh!t and the, well, the new kids on the block are attempting to re-solve the problem, thinking that they'll do better... but probably weren't even aware that it was solved before. what was that about repeating the same thing and expecting a different output being the first step into madness...
This is also a good reason for not doing a native installation, but using docker - I hated typing that - but that is the reality, you isolate out the components and dependencies. sigh.... do I need to do a docker install now? I could do a Python Virtual Environment (venv), where I create multiple instances of Python and I could have a Python 3.11 inside one of those... sigh.. it's a workaround, but it'd work and wouldn't have the overhead or dependency of using docker...
First big question is: do I REALLY need Python 3.11? can I use 3.10 and get away with it? probably not - probably down to the internal dependencies of all of those libraries contained within the requirements.txt file - and there is a LOT.
bugger - okay, here goes... Python 3.11 in a venv.
Or, maybe not...... I'm running UBuntu 22.04 in this VM image, so I can potentially follow THIS set of instructions and have 3.11 in the next 10 mins (we'll see).
sudo add-apt-repository ppa:deadsnakes/ppa
sudo apt update
sudo apt install python3.11

A quick sanity / verification check:

Okay, but I don't want to type Python 3.11 every time, so how do I tell my machine to use the Python 3.11 as the default, well, as per that website, do the following:

there we go:

Thankfully, I have cleaned up this VM Ubuntu image, so it doesn't matter about making this change, but you can image if I had any other apps that were dependent on Python 3.10, they will now be broken. Fortunately, I'm okay with a clean-ish install. Should really have done the UBuntu 23 install and then would have hit the other pip problem (that's for another day!)
Okay, back to what we're meant to be doing:
$ mkdir dev
$ cd dev
$ git clone https://github.com/open-webui/open-webui.git
$ cd open-webui/
# Copying required .env file
$ cp -RPp example.env .env
# Building Frontend Using Node
$ npm i
$ npm run build
The above will generate a build directory where the front-end code will execute from. During the development change cycle, we will delete the build directory (after we've modified the source code) and then re-run the above 2 commands to generate the output.

Now onto the backend.
# Serving Frontend with the Backend
$ cd backend
$ pip install -r requirements.txt -U
$ sh start.sh
I found that the requirements.txt list of libraries is loooooooooooooooong, so keep an eye out for anything that zooms up the screen in RED - that's a failure.
Well, there you go, first error:

Looks like my previous code/libraries may have left some specific DLL HELL versions lying around.
looks like peewee and pypika build wheels failed to execute, so "rain stopped play". investigation time.
This looks like a Python rabbit-hole of hell. So, I'm going to switch to my Raspberry Pi 5 8Gb device where I have done ALL OF THESE STEPS in a clean / new / fresh UBuntu 23 and it is all working fine - I'm not going to burn hours / days attempting to fix Python crap if I don't need to. But, be warned THIS is exactly why I don't like Python, I needs / wants you to basically burn your existing environment and always install from fresh for anything to work - that sucks & isn't realistic. Also, I don't have the time or patience to dig any further, nor should I have to.
I also found that due to the usage of vunicorn, I had to perform a machine restart and then I could access the app okay.
The FIRST registered account is the ADMIN account - remember the credentials that you have used - this is important! If you forget, you will need a complete from the ground-up re-do.
The first time you run $sh start.sh required files will also be downloaded as shown here:

Open web-browser to http://localhost:8080 and you will see the login screen. Now you can run in offline mode from this point forward.
Now...what can you do with this?
Well, you now have a FAST offline way to communicate with LLM models using just CPUs (bonus if you do have a GPU on your machine - makes it a LOT faster, like instant response!)
You can ingest your own documents - RAG style - so you can ask questions about specific documents or collections of documents and get the LLM model to give you responses about questions / summaries etc.. specifically about the chosen document content
You can build out pre-build PROMPTs that can be used as templates for repeated usage style questioning that you may do, with a dynamic entry
You can see a history of your chats with the LLM models - you can even export them / save them
and the one I like the most (although this is best run in a GPU environment) is to load up 3-4 different LLM models and ask a question and see the differences in the responses from each model. This is a really great PoV, as it will start to guide / shape you onto which model is going to be the most useful for you - for your usage or the style output that you are looking for.
Right, I now have to take a look at making a fwe code enhancements, sucha s raised by issue 774 and feature request 715. Amusingly, I could just sit back & wait for the code to get changed, probably be available next week - or I could get under the bonnet and have a look at it myself.
As mentioned previously, I actually did a vast amount of work with Langchain previously, so I need to dig out that code and look at grafting it into this codebase to pump it full of steroids. Why don't I do a PR and make it official. Can't, locked down by my employer, I do stick within certain boundary of rules believe it or not.
One feature that would be "really good" is to have the ability to ingest 1000s of documents from a directory and sub-directories without having to use the UI - again, cough cough, something I wrote, back in August '23 for something else - just have to graft it onto/into this codebase and it solves a lot of problems.
Right, time for a cup of tea and time to get busy.
UPDATE:
So...I'm going to focus on the RAG aspects here, for instance, uploading a few documents into different categories / assigning tags to them so I can pick either from [all documents] or from [subsets].
Now, as I'm a retro-geek, I've uploaded a few PDF documents of old Amstrad CPC 464 books (from the mid-1980s):

I had a look at the backend source code, mainly the main.py file from /backend/apps/rag/main.py

As you can see, the /query/collection API code makes a call to langchain to perform a collection.query() and pass the result back as, well the "results" variable - after doing the merge and sort on the data first.
Interestingly, this data actually contains ALL of the information about what documents were identified to be relevant, what pages the relevant sections are & what snippet of text makes it relevant, along with the "distances" data (relevancy).This is shown in the debug on the right-hand side of the following screenshot:

Now, that was not output normally, I had to find where to do it.
There are actually 2 locations where the [sendPrompt] code is located, the "wrong one" (and I'll dig in later to find out why it's wrong) is located in the sub-folder named "c", "[id]", "+page.svelte".
The "right one" is the one in the root level as shown.

As you can see, just dropping a few console.log outputs and changing the call to queryCollection() to return to an object rather than directly return it - this way, we've captured the "results" returned from the backend API call.

Now that we have that data in that object, we are in the output page therefore we can now output to the screen before we output the "AI Thought" output.
I'll update shortly the code where I put this into the UI - once that is done, it'll be pretty cool & do what I actually want it to do.



Comments
Post a Comment